최초 작성일: 2024-10-09
최종 작성일: 2024-10-09
목표 : 정처기 합격 및 CS 지식 쌓기
데이터 베이스 구축 3~4 문제
1. 데이터베이스 개념
(1) 데이터와 정보
데이터 : 관찰을 통해 수집한 값
정보 : 데이터를 처리한 결과물
(2) 데이터 베이스의 정의(공장통운)
공유 데이터 : 여러 사용자가 공동으로 사용하는 데이터
저장 데이터 : 저장 매체에 저장된 데이터
통합 데이터 : 중복이 최소화된 데이터 모임
운영 데이터 : 조직의 목적을 위한 필수 데이터
(3) 데이터 베이스의 특징
실시간 접근성
계속적인 변화
동시 공유
내용에 의한 참조
데이터의 독립성 – 논리적, 물리적 독립성
(4) 데이터 언어 (상암 DMC)
DDL : 구조와 제약 조건 정의 (통을 만드는 것)
DML : 데이터 처리 및 조작 (SELECT)
DCL : 보안, 권한, 무결성 및 병행 제어 (GRANT,REBOVE,COMMIT, ROLLBACK)
(5) 스키마
1) 정의 : 스키마는 데이터베이스의 구조, 제약조건, 속성, 개체, 관계를 포함한 전반적인 명세를 기술한 것이다
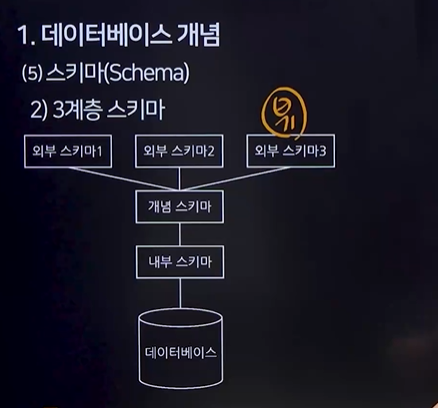
2) 3계층 스키마
외부 스키마(사용자 뷰, 여러 벌 일 수 있음) – 개념 스키마(전체적인 구조, 제약 조건- 한번 밖에 없음) – 내부 스키마(메타 데이터) -데이터 베이스
논리적 독립성: 개념 스키마가 바뀌어도 외부 스키마에 영향을 주지 않는다
물리적 독립성: 내부 스키마가 바뀌어도 개념 스키마에는 영향을 주지 않는다
2. 데이터베이스관리 시스템
(1) 정의 : DBMS는 데이터 베이스를 효과적으로 관리하고 조작하기 위한 전용 소프트웨어
(2) 기능: 정의, 조작, 제어, 공유, 보호, 구축, 유지보수
(3) 종류
1) 계층형 : 트리 구조 (다대다 관계 불가능)
2) 네트워크형: 다대다 관계 가능
3) 관계형 : 데이터 구조의 모델
4) 객체 지향형 : 객체지향 프로그래밍 개념에 기반
5) 객체 관계형 : 관계형 + 객체지향형
6) No SQL (Not Only SQL) : 다양한 특성을 지원
7) New sql : RDBMS + NoSQL
1. 데이터 베이스 설계 개요 (통을 설계,개념-> 논리 -> 물리 설계)
(1) 설계 정의
데이터 베이스 설계는 요구조건에서부터 데이터베이스 구조를 도출하는 과정
(2) 설계 시 고려 사항
제약조건(남,녀), 데이터베이스 무결성, 일관성, 회복, 보안, 효율성, 데이터베이스 확장성
2. 데이터베이스 설계 단계
(1) 요구조건 분석
(2) 개념적 설계 : 개념적 스키마 구성 (ERD)
(3) 논리적 설계
현실 세계의 요구사항과 목표 데이터 모델(관계형 등)기반 설계,
정규화(관계형 일때), 트랜잭션 인터페이스 설계
(4) 물리적 설계 : 구조 및 성능에 대한 설계/ 반정규화
(5) 구현
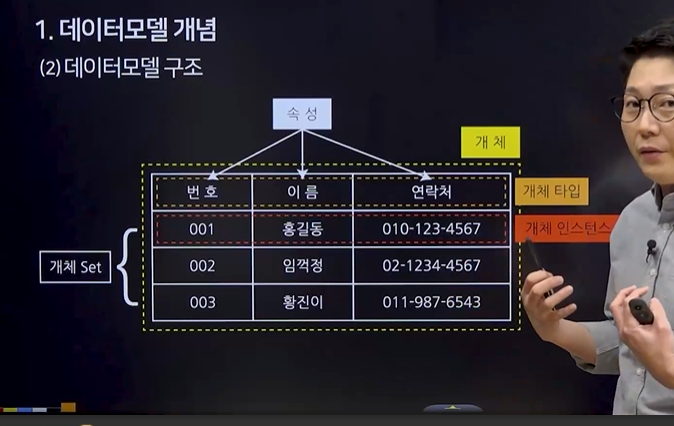
3. 데이터 모델 개념
(1) 개념 : 현실 세계의 복잡한 데이터 구조를 단순화, 추상화 하여 체계적으로 표현한 개념적 모형
(2) 데이터 모델 구조
개체
개체 타입
개체 인스턴스
속성
(3) 데이터 모델에 표시해야할 요소
구조 : 데이터 구조 및 개체 간 관계
연산(Operation) : 데이터 처리 방법
제약 조건 (Constraint) : 데이터의 논리적 제약 조건
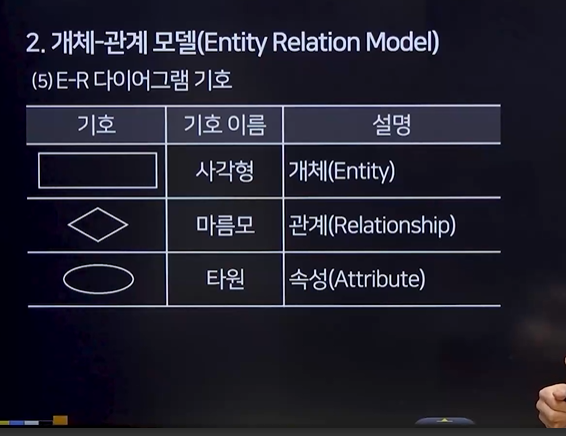
4. 개체- 관계 모델 (ERM)
(1) 개체-관계 모델 개념 : 데이터베이스의 요구사항을 그래픽적으로 표현하는 모델
(2) 개체(Entity) : 현실 세계의 독립적이고 구별가능한 대상 – 네모
(3) 애트리뷰트, 속성 – 동그라미
개체나 관계의 고유한 특성을 나타내는 정보의 단위
단일값 속성, 다중 값 속성, 단순 속성, 복합 속성, 유도 속성(다른 것들로부터 유도되는, 주민등록번호가 1로 시작 -> 남자), 널 속성, 키 속성(나를 인식할 수 있는)
(4) 관계 : 두 개체 간의 의미 있는 연결 – 마름모
5. 데이터 모델의 품질 기준 (정완준최일활)
정확성: 요구사항을 정확하게 반영
완전성: 요구사항이 완전하게 반영
준거성: 준수 요건들이 정확하게 준수
최신성: 현재의 시스템의 상태와 최근의 이슈사항을 반영
일관성: 데이터 요소의 일관성 유지
활용성: 이해 관계자에게 의미전달이 용이
6. 논리적 데이터 모델링
(1) 논리적 모델링 : 개념적 설계 단계에서 도출된 개체, 속성, 관계를 구조적으로 표현하는 과정( 이 단계에서는 목표 DBMS에 맞는 정규화, Transaction interface 설계 필요하며, 목표 DBMS가 보통 관계형이라 논리적 모델링을 표 형태로 그리는 경우가 많음)
7. 데이터 베이스 정규화 ( 공장통운 – 통합_중복을 제거하는)
(1) 정규화의 개념 : 관계형 데이터베이스의 설계에서 데이터 중복을 최소화 하기 위한 과정
왜 수행? 무결성과 일관성을 위해 수행함. 중복 -> 이상현상 발생 -> 이상 현상 최소화 하기 위한 정규화
(2) 목적
데이터 중복 최소화
이상현상 최소화
정보의 무손실: 정보가 사라지지 않아야 함
독립적인 관계는 별개의 릴레이션으로 표현
검색 용이성 증가
(3) 이상현상(Anomaly) – 삽입, 삭제, 갱신
데이터 중복으로 인해 릴레이션 조작 시 발생하는 예기지 않은 문제점
이상의 종류
-삽입이상: 불필요한 데이터가 함께 삽입되는 현상
-삭제 이상 : 연쇄 삭제 현상으로 인해 정보 손실
-갱신 이상: 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 형상
(4) 함수적 종속
1) 개념 : 어떤 릴레이션 R(이라는 테이블)의 X와 Y를 각각 속성의 부분집합이라고 가정했을 때
-X의 값을 알면 Y의 값을 바로 식별할 수 있고,
X의 값에 Y의 값이 달라질 떄, Y는 X에 함수적 종속이라고 함
-이를 기호로 표현하면 X(주민번호)->Y(이름)
2) 함수적 종속 관계
-완전 함수적 종속 : 종속자가 기본키에만 종속(내 주민번호를 가지고 이름이나 주소를 식별할 수 있음)
-부분 함수적 종속 : 기본 키를 구성하는 속성 중 일부만 종속되는 경우 ( 학생의 특별한 과목이 알고 싶은 경우, 학번과 과목번호를 알아야함. 그래서 해당 정보를 알고 싶을 떄 학번과 과목번호가 키일 때 학번만 가지고도 이름을 알 수 있을 때. 그래서 학번과 이름 학번과 과목 점수로 만들어서 완전 함수적 종속 관계를 만들 수 있음)
-이행적 함수 종속 : X->Y->Z일 때, X->Z가 성립되는 경우
(5) 정규화 과정
1정규형 : 도멘인이 원자값 ( 이름, 취미- 등산, 걷기, 소주 등일 때, 그럼 취미가 원자 값이 아님 -> 취미를 등산, 걷기, 소주를 각각의 개체로 만드는 것)
2정규형: 부분적 함수 종속 제거
3정규형: 이행적 함수 종속 제거
도부이결다조
8. 물리 데이터 베이스 설계
(1) 설계 과정
사용자 DBMS 결정
데이터 타입과 그 크기 결정
데이터 용량 예측 및 업무 프로세스 분석 (crud)
역정규화(반정규화)
인덱스 설계
데이터베이스 생성
9. 반정규화
(1) 개념 : 성능향상이나 개발 및 운영의 편의성을 위해 의도적으로 중복을 허용하거나 데이터를 재구성하는 기법 (예를 들어 회원이랑 주문 테이블이 있을 때, 자주 검색하는 회원정보를 주문 테이블에 넣어서 기능 향상을 함)
(2) 반정규화의 적용 순서
반정규화 대상 조사
다른 방법으로 유도 ( 파티션, 클러스터, 뷰, 인덱스 설정 등을 해보고)
반정규화 수행
(3) 반정규화의 유형
테이블 분할 (수형, 수직)
테이블 중복 (통계 테이블, 진행 테이블)
컬림 기반 분할
컬럼 중복
10. 데이터 베이스 이중화 f/w L4 (W1,W2) DB -> 고가용성
(1) 이중화 구성
장애에 대비하여 동일한 데이터베이스를 중복하여 관리하는 방식
(2) 데이터베이스 이중화의 목적
장애나 재해 발생 시 빠른 서비스 재개/ 서비스의 원활한 성능 보장
(3) 데이터베이스 이중화의 분류
Eager 기법: 트랜잭션 발생 시 즉시 반영
Lazy 기법: 트랜잭션 완료 후 반영
11. 데이터베이스 백업
(1) 개념
데이터를 주기적으로 복사하여 보관하는 것
백업: 데이터를 복사하여 보관하는 과정
복원: 손상된 데이터베이스를 원래 상태로 되돌리는 과정
(2) 백업 방식
1) 전체 백업 : 모든 데이터를 백업
2) 증분 백업 : 변경/추가된 데이터만 백업
3) 차등 백업 : 모든 변경/추가된 데이터를 백업
4) 합성 백업 : 전체 백업 본과 여러 개의 증분 백업을 합하여 새로운 전체 백업을 만드는 작업
(3) 복구시간목표/복구 시점 목표
1) 복구 시간 목표(RTO)
서비스를 사용할 수 없는 상태로 허용되는 기간
2) 복구 시점 목표(RPO)
마지막 백업 이후 허용되는 최대 데이터 손실 시간
12. 데이터 베이스 암호화
(1) 개념 : 데이터베이스 내용을 암호화 하는 과정
(2) 암호화 방식
API 방식 : 애플리케이션에서 수행
PLUG-IN 방식: DB 서버에 제품 설치 후 수행
TDE 방식 : DBMS 내부의 기본 모듈로 수행
13. 파티셔닝
(1) 개념 : 데이터 베이스의 특정 부분(데이터)을 여러 섹션으로 분할 하는 방법
(2) 샤딩: 거대한 데이터베이스를 조각(샤드)으로 나누어 분산 저장 및 관리하는 기법 ( 파티셔닝은 하나의 DB에서 사용하고 샤딩을 분산 환경에서 수행함)
(3) 파티셔닝의 종류
1) 수평 분할
2) 수직 분할
(4) 분할 기준
1) 범위 분할 (RANGE)
2) 목록 분할
3) 해시 분할
4) 라운드 로빈 분할
5) 합성 분할
14. 클러스터 설계
(1) 개념 : 자주 사용되는 테이블의 데이터를 디스크 상 동일한 위치에 저장하여 데이터 엑세스 효율을 향상시키는 물리적 저장 방법
15. 인덱스
(1) 개념 : 데이터 베이스 테이블 검색 속도 향상을 위한 저장 공간 활용 자료 구조
(2) 인덱스의 종류
1) 클러스터 인덱스 : 테이블 당 1개만 허용되며, 해당 칼럼을 기준으로 테이블이 물리적으로 정렬 ( 물리적인 테이블의 순서를 정렬)
2) 넌 클러스터 인덱스 : 테이블 당 약 240개의 인덱스 생성 가능/레코드의 원본은 정렬되지 않고, 인덱스 페이지만 정렬 (물리적인 테이블을 못건드림)
3) 밀집 인덱스 : 데이터 레코드 각각에 대해 하나의 인덱스가 만들어짐
4) 희소 인덱스 : 레코드 그룹 또는 데이터 블록에 대해 하나의 인덱스가 만들어짐
(3) 인덱스 구조
1) 트리 기반 인덱스
2) 비트맵 인덱스
3) 함수 기반 인덱스
4) 비트맵 조인 인덱스
5) 도메인 인덱스
16. 뷰 ( 가상의 논리적 테이블)
(1) 개념 : 기본 테이블에서 유도된 이름이 있는 가상 테이블
17. 시스템 카탈로그(사용자가 볼 수 는 있으나 수정할 수는 없음)
(1) 개념 : 데이터베이스의 모든 데이터 개체들에 대한 정보를 저장한 시스템 테이블로 데이터 사전 이라고도 한다
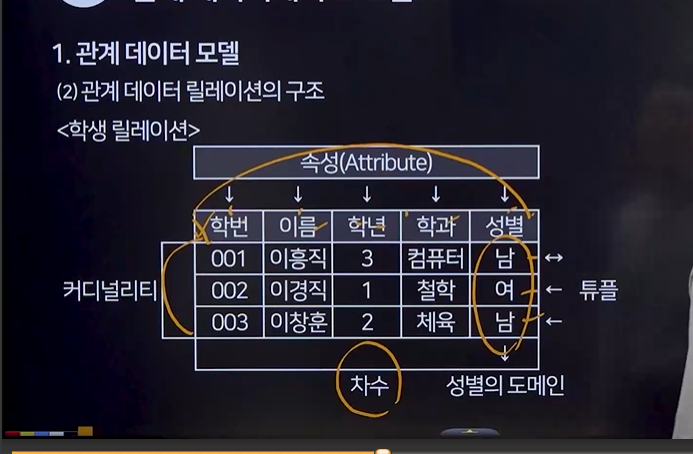
18. 관계 데이터 모델
(1) 개념 : 데이터의 논리적 구조를 테이블 형태로 표현/ 테이블은 튜플(행,레코드)과 속성(열,칼럼) 구성 된다.
(2) 구조
속성 : 릴레이션의 열, 개체의 특성
튜플 : 릴레이션의 행, 속성들의 모임
도메인 : 속성이 가질 수 있는 값의 범위
차수 : 속성의 총 개수
카디널리티 : 튜플의 총 개수
(3) 릴레이션 (데이터 덩어리)
데이터들을 2차원 테이블의 구조로 저장한 것
릴레이션의 구성
-스키마 : 릴레이션의 논리적 구조
-릴레이션 인스턴스 : 스키마에 실제로 저장된 데이터의 집합
19. 관계 데이터 언어(관계 대수- 절차적 언어, 관계 해석- 비절차적 언어)
(1) 관계 대수의 개념 : 원하는 데이터를 찾지 위한 절차적 언어
(2) 순수 관계 연산자
-SELECT : 시그마
-PROJECT( 각각의 열들을 가져와) : 파이
-JOIN ( 두 테이블을 조합) : 보타이
-DIVISION( 연관 관계 가져오는 것 ) : 나누기
(3) 일반 집합 연산자 -> 연산자 확인 필요
합집합
교집합
차집합
교차곱 : 모든 가능한 조합들
(4) 관계 해석 -> 연산자 확인 필요
원하는 정보가 무엇인지라는 것만 정의하는 비절차적 특성
튜플 관계해석과 도메인 관계 해석이 있다
20. 키와 무결성 제약 조건
1. 속성(컬럼)
(1) 개념 : 정보의 최소 단위/ 컬럼을 속성이라고도 한다
(2) 속성의 분류
기본 속성: 업무로부터 추출한 모든 속성
설계 속성: 코드성 데이터
파생 속성: 다른 속성에 영향을 받아 발생하는 속성
2. 키 종류
(1) 키의 개념 : 튜플을 식별하고 구별하는 데 사용되는 칼럼
(2) 키의 종류 : 슈퍼키(유일성-나만 특정), 후보키(유일성과 최소성 충족, 기본 키가 될 수 있는 후보키), 기본키(유일성과 최소성), 대체키(후보키에서 기본키를 제외한것으로 유일성과 최소성을 충족시켜야함)
21. 데이터베이스 무결성
(1) 개념 : 데이터의 정확성, 일관성 및 유효성을 보장하는 데이터베이스 관리시스템의 중요한 기능
(2) 무결성의 종류
1) 개체 무결성 : NULL 불가, 중복 불가
2) 참조 무결성 : 외래키는 NULL이거나 참조 릴레이션의 기본키와 일치해야함 ( 1,2,3번 주문이 있고 주문 번호별 상품이 있는 경우, 참조해야하는 테이블에 값이 있어야 함) / Restrict,(참조한 값을 삭제하면 안됨, 연쇄삭제) Cascade(삭제 제한)
3) 도메인 무결성 : 속성 값은 정의된 도메인에 속해야한다 (성별이라는 속성이 있다면 해당 속성의 도메인에 있는 남,여만 써야함)
4) 고유 무결성(유니크) : 릴레이션의 특정 속성 값은 서로 달라야 한다 ( 전화 번호 같은 것은 중복 되면 안됨)
5) 키 무결성 : 각 릴레이션은 적어도 하나의 키를 가져야 한다
6) 릴레이션 무결성 : 삽입, 삭제, 갱신 등의 연산은 릴레이션의 무결성을 해치지 않도록 수행 되어야 한다 (연산 전 후에 값이 같아야 함)
22. CRUD 분석
(1) 개념 : 해당 업무에 어떤 데이터가 존재하는 지 무엇이 영향을 받는 지 분석
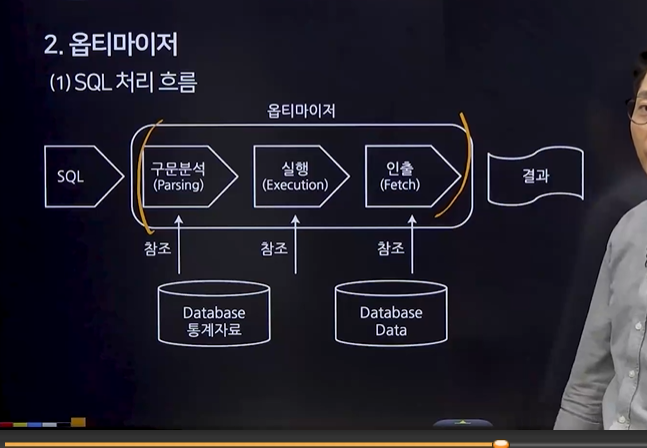
23. 옵티마이저
(1) SQL 처리 흐름 (인출은 SELECT에서만 수행) : 구문 분석 -> 실행 -> 인출
(2) 옵티마이저 개념
SQL문에 대한 최적의 실행 방법을 결정
옵티마이저의 구분
- 규칙 기반 옵티마이저 : 규칙(우선순위)을 가지고 실행 계획을 생성
- 비용 기반 옵티마이저 : 소요시간이나 자원 사용량을 가지고 실행 계획 생성 (통계 자료가 있어야 함. 통계자료를 활용함)
24. SQL 성능 튜닝
(1) 튜닝의 개념
SQL문을 최적화하여 시스템의 처리량과 응답속도를 개선하는 작업
(2) 튜닝 영역
데이터베이스 설계 튜닝
데이터베이스 환경
SQL 문장 튜닝
25. 분산 데이터 베이스
(1) 정의 : 여러 곳에 분산된 데이터 베이스를 하나의 논리적인 시스템 처럼 사용할 수 있는 데이터 베이스
(2) 구성 요소 : 분산 처리기, 분산 데이터베이스, 통신 네트워크
(3) 투명성 조건
위치 투명성(Location): 실제 위치를 모르고 액세스 가능
분할 투명성(Division) : 여러 단편으로 분할
지역사상 투명성(Local Mapping) : 각 지역시스템 이름과 무관하게 사용
중복 투명성(Replication) : 데이터의 중복을 사용자에게 숨김
병행 투명성(Concurrency) : 다수의 트랜잭션들이 동시에 실행되어도 영향을 주지 않음
장애 투명성(Failure) : 다양한 장애에도 트랜잭션 처리
(4) CAP 이론
1) 개념 : 어떤 분산 환경에서도 일관성©, 가용성(A), 분단 허용성(P) 세가지 속성 중 두가지만 가질 수 있다는 것
26. 트랜잭션
1) 개념 : 하나의 논리적 기능을 수행하는 작업 단위
2) 트랜잭션의 성질
원자성(Atomicity): 모두 반영되거나 아니면 전혀 반영되지 않아야 한다 (commit, rollback에 영향을 받는 것)
일관성(consistency): 트랜잭션의 완료 후에는 데이터베이스가 일관성을 유지 해야한다
독립성, 격리성(solation) : 동시에 실행되는 여러 트랜잭션들은 서로 간섭할 수 없다 ( 하나의 트랜잭션이 수행중일떄 다른 트랜잭션에 영향을 주어서는 안됨)
영속성(durability) : 결과는 시스템에 고장이 발생해도 영구적으로 반영되어야 한다 (commit후에는 데이터가 영구적으로 반영되어야 한다)
(3) 트랜잭션의 상태
활동(active) : 트랜잭션이 실행 중인 상태
실패(failure) : 트랜잭션 실행에 오류가 발생하여 중단된 상태
철회(aborted) : 비정상적으로 종료되어 rollback 연산을 수행한 상태
부분 완료(partially committed) : commit 연산이 실행되기 직전의 상태
완료(committed) : 트랜잭션이 성공적으로 종료된 상태(commit 완료)
27. SQL
(1) 개념 : DB시스템에서 데이터를 처리하기 위해 사용되는 구조적 데이터 질의 언어 (정조제 언어)
(2) 종류
DDL/DML/DCL
28. 저장 프로시저(stored procedure)
(1) 개념 : 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
29. 트리거
(1) 개념 : 테이블에 대한 이벤트에 반응해 자동으로 실행되는 작업
(2) 트리거의 유형
행 트리거 : for each row 옵션 사용
문장 트리거 : 문장에 대해서 한번만 수행
30. 사용자 정의 함수
(1) 개념 : 프로시저와 사용자 정의 함수 모두 호출하게 되면 미리 정의해 놓은 기능을 수행하는 모듈 (함수의 경우, return 값이 없거나 하나만 있음)
31. 병행 제어
(1) 개념 : 여러 트랜잭션이 동시에 실행되면서 데이터 베이스의 일관성을 유지하는 기법
(2) 문제점
1) 갱신 분실 : 일부 갱신 결과가 손실 되는 현상(하나의 데이터)
2) 비완료 의존성 : 실패한 트랜잭션의 결과를 다른 트랜잭션이 참조하는 현상
3) 모순성 : 병행 수행 중 원치 않는 자료를 사용함으로 써 발생하는 문제(여러 개의 데이터를 사용할 떄)
4) 연쇄 복귀 : 하나의 트랜잭션이 실패해 롤백되면 다른 트랜잭션도 함께 롤백되는 현상
(3) 병행제어 기법
1) 로킹 (locking)
2) 2단계 로킹 규약 : 확장 단계(락인)와 축소 단계(락해제)가 있음
3) 타임스탬프 : 시간을 자르는
4) 낙관적 병행제어
5) 다중 버전 병행제어 : 여러 개의 타임스탬프
32. 회복(database recovery)
(1) 개념 : 장애로 인해 손상된 데이터베이스를 이전의 정상상태로 복구하는 작업
(2) 유형 : 트랜잭션 장애/ 시스템 장애/ 미디어 장애
(3) 회복 기법
1) 로그 기반 회복 기법
지연갱신회복기법(deferred) : 트랜잭션 완료 후에 DB에 반영
즉시갱신회복기법 : 그때 그때 반영 (REDO, UNDO)
2) 검사점 회복 기법(Check point)
3) 그림자 페이징 회복 기법(shadow paging, 복사본 만드는 것)
4) 미디어 회복 기법 (카세트 테이프에 저장)
5) ARIES 회복 기법(알고리즘 사용)
33. ETL
(1) 개념 : 데이터 전환을 기존 원천 시스템에서 데이터를 추출하고 이를 목적 시스템의 데이터 베이스에 적합
34. 데이터 정제
(1) 데이터 품질 관리 대상
데이터 값
데이터 구조
데이터 관리 프로세스
l 파티셔닝,클러스터, 인덱스, 뷰 모두 검색 속도 향상을 위한 것이며 이렇게 해도 검색 속도 향상이 되지 않아 반정규화를 수행하는 것임
l 운영 체제의 경우, PCB(문맥교환), FD(파일 디스크립터, 파일 관리), 시스템 카탈로그(DBMS가 DB관리 목적)





'스터디스터디 > 정처기' 카테고리의 다른 글
| [실기] 운영체제 (7) | 2024.10.11 |
|---|---|
| /wip/ [실기] 운영체제 (1) | 2024.10.11 |
| [실기] 소프트웨어공학(3/3) (8) | 2024.10.07 |
| [실기] 소프트웨어공학(2/3) (3) | 2024.10.06 |
| [실기] 소프트웨어공학(1/3) (5) | 2024.10.06 |


