최초 작성일: 23년 1월 23일
최종 작성일: 23년 1월 26일
목적
- internal table별 creating internal table을 자유롭게 하기
- internal table을 만들고 수정 등의 작업을 하는데 사용되는 모든 구문들을 이해하기
01.overview
01-1.internal table의 정의
internal table은 프로그램 내에서 정의하여 사용할 수 있는 local table이다.
01-2. structure(구조체) 비교
01-3. structure(구조체) 배열과 internal table
<ABAP에서 인터널 테이블 선언>
TYPES: BEGIN OF s_type,
NO(6) TYPE C,
NAME(10) TYPE C,
PART(16) TYPE C,
END OF s_type.
TYPES t_type TYPE STANDARD TABLE OF s_type INITIAL SIZE 100.
DATA sawon TYPE t_type.<ABAP언어>
- 선언: DATA 테이블명 TYPE 테이블 타입, INITIAL SIZE건수.
- 값 할당
sawon-name ='OHJOOYONG',.
APPEND sawon.
sawon-name = 'hongminji'.
APPEND sawon- 값 사용
LOOP AT saewon,
WRITE saewon-name,
END LOOP.인터널 테이블은 INITIAL SIZE구문으로 테이블 크기만 선언할 뿐 미리 메모리에 Load하지 않는다.
따라서 insert 또는 append 구문을 사용하여 line이 추가될때 마다 메모리에 load 한다.
이러한 측면에서 인터널 테이블은 동적인 구조체 배열(dynamic data object)이라고도 정의한다.
- internal table은 동적인 구조체 배열(dynamic data object)이다.
- initial size구문은 실제로 메모리 공간을 할당 하는 것이 아니라 예약(reserve)한다.
인터널 테이블은 항상 할당과 추가(append)구문이 쌍으로 움직여야 한다.
01-4. internal table 생성
- local table type을 이용한 인터널 테이블 생성
TYPES: BEGIN OF s_type,
no(6) TYPE C,
name(10) TYPE c,
part(16) TYPE C,
END OF s_type.
DATA gt_itab TYPE STANDARD TABLE OF s_type WITH HEADER LINE.
gt_itab-no = '7288'.
gt_itab-name = 'minji'.
gt_itab-part = '1720'.
APPEND gt_itab.
LOOP AT gt_itab.
WRITE: gt_itab-no, gt_itab-name, gt_itab-part.
ENDLOOP.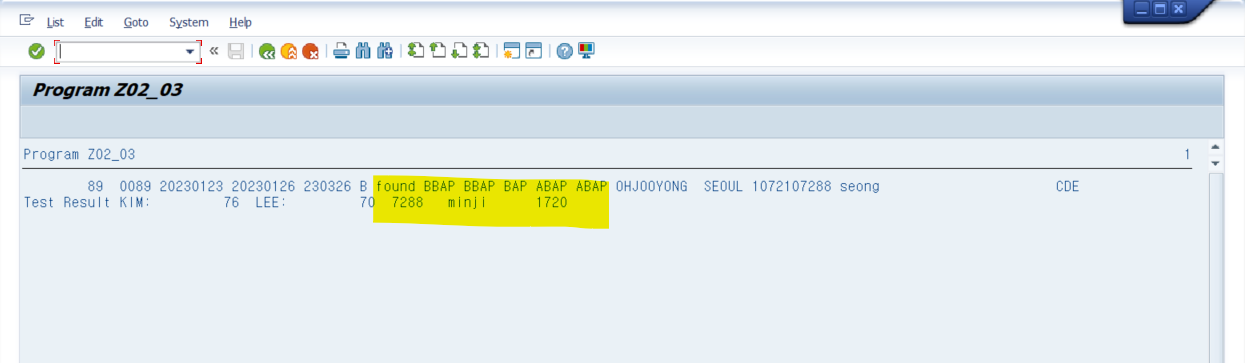
- global abap dictionary type을 이용한 인터널 테이블 생성
DATA gs_itab TYPE SORTED TABLE OF scarr with UNIQUE key carrid.
DATA gs_str LIKE LINE OF gs_itab.
SELECT * INTO TABLE gs_itab
FROM scarr.
LOOP AT gs_itab INTO gs_str.
WRITE: gs_str-carrid, gs_str-carrname.
ENDLOOP.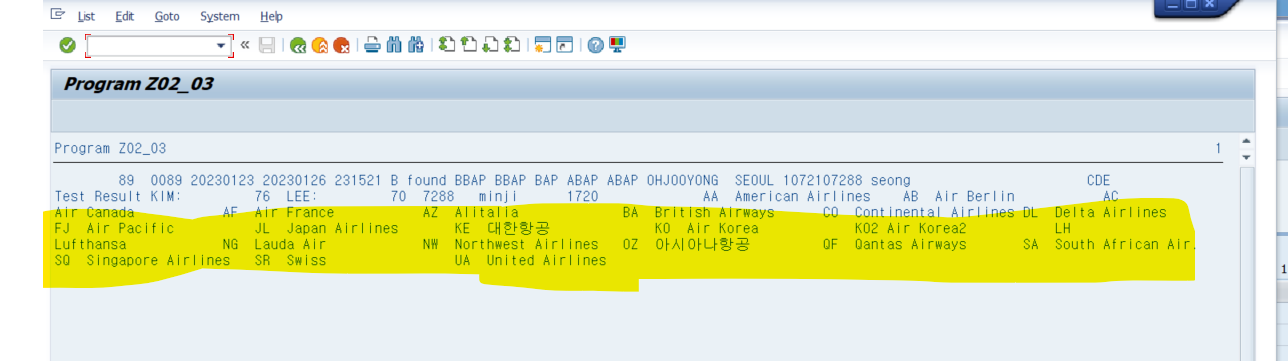
**LOOP AT 구문이 이해가 안되는 시점에 찾은 블로그!!
[한설날][ABAP] LOOP 문 (tistory.com)
02.인터널 테이블과 헤더라인
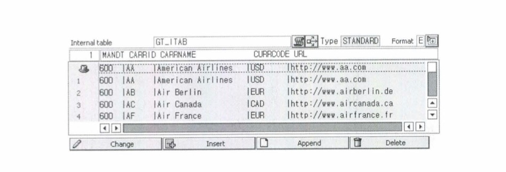
헤더라인은 work area라고도 한다.
인터널 테이블 선언 시 'WITH HEADER LINE'구문을 추가 하여 생성하면 헤더라인을 생략할 수 있다..
(근데 with header line구문을 추가 하면 into WA(work area)를 생략해도 된다고 하는데, into 뒤에 wa가 조건에 맞는 걸 임시로 저장하여 실행문을 실행하는 거라면, header line과 WA의 상관관계를 잘 모르겠다..)
LOOP AT gt_itab INTO gt_str
[WHERE 조건]
[FROM start_idx TO end_idx].
[실행문]
ENDLOOP.
**인터널 테이블 GT_ITAB의 조건에 부합하는 레코드 들 중에서 START_IDX부터 END_IDX 까지의 레코드를 차례대로
스트럭쳐 GS_STR에 담아 실행문을 실행 한다.
*gt_str = WORK AREA = HEADER LINEREPORT Z02_03.
*with header line
TYPES: BEGIN OF t_str,
col1 TYPE i,
col2 TYPE i,
END OF t_str.
DATa gt_itab TYPE STANDARD TABLE OF t_str WITH HEADER LINE.
DO 3 TIMES.
gt_itab-col1 = sy-index.
gt_itab-col2 = sy-index ** 2.
APPEND gt_itab.
ENDDO.
LOOP AT gt_itab .
WRITE:gt_itab-col1, gt_itab-col2.
ENDLOOP.
*with no header line.
TYPES: BEGIN OF s_str,
col1 TYPE i,
col2 TYPE i,
END OF s_str.
DATA gv_itab TYPE STANDARD TABLE OF s_str.
DATA sv_str LIKE LINE OF gv_itab.
DO 3 TIMES.
sv_str-col1 = sy-index.
sv_str-col2 = sy-index ** 2.
APPEND sv_str TO gv_itab.
ENDDO.
LOOP AT gt_itab into sv_str.
WRITE:sv_str-col1, sv_str-col2.
ENDLOOP.03.인터널 테이블 종류
03-1. standard table
TYPES: BEGIN OF t_line,
field1 TYPE C LENGTH 5,
field2 TYPE C LENGTH 3,
field3 TYPE C LENGTH 4,
END OF t_line.
**STANDARD TABLE 선언
TYPES:t_itb TYPE STANDARD TABLE OF t_line WITH NON-UNIQUE DEFAULT KEY.
**INTERNAL TABLE
DATA t_itab TYPE t_itb WITH HEADER LINE.
t_itab-field1 = 'enjoy'.
t_itab-field3 = 'ABAP'.
APPEND t_itab.
READ TABLE t_itab INDEX 1.
write: t_itab-field1, t_itab-field3.WITH NON-UNIQUE DEFAULT KEY의 역할은 인터널 테이블의 char타입으로 선언된 모든 칼럼들을 키 칼럽으로 정의하는 것이다.
with unique default key 구문을 선언하지 않아도 기본으로 포함된 것으로 간주되며 이러한 key를 standard key라고 한다.
READ TABLE 구문은 인터널 테이블의 개별 LINE에 접근하는 문장으로 SELECT 문장을 사용하는 것과 유사하다.
READ TABLW ~ INDEX1 구문은 인터널 테이블의 1번째 Line 데이터를 읽는다.
standard table은 index를 이용하여 검색하기 때문에 테이블의 라인 수에 비례하여 탐색 속도가 증가한다. 인터널 테이블의 순서가 아니라, 칼럼 값을 기준으로 데이터를 읽을 때는 다음과 같이 사용된다.
READ TABLE gt_itab WITH TABLE KEY field1 = 'Enjoy' field2 ='ABAP'.
READ TABLE gt_itab WITH KEY field3 =1.
READ TABLE gt_itab INDEX2.03-2.sorted table
standard table과 sorted table은 index 테이블이다.
그중 sorted table은 key값으로 항상 정렬된 인터널 테이블 타입이다.
즉, 프로그래머가 원하는 key값으로 항상 정렬된 결과로 인터널 테이블에 저장해야하는 경우에 사용한다.
standard table과 마찿ㄴ가지로 index를 가지고 있으며, index 또는 key로 해당 row를 찾아갈 수 있다.
sorted table과 standard table의 차이점은 uniqueness이다.
sorted table은 key값을 선언할때, with unique를 사용할 수 있지만, standatd table은 with non unique 만 사용할 수 있다.
sorted table은 내부적으로 binary research를 이용하기 때문에, table entry의 수와 탐색속도는 정적 상관관계를 같는다.
sorted table로 선언할 때는 unique/ non- unique를 반드시 명시하여야 한다.
types: BEGIN OF s_line,
col TYPE C,
seq TYPE i,
END OF s_line.
TYPES s_tab TYPE SORTED TABLE OF s_line WITH unique key col.
DATA s_itab TYPE s_tab WITH HEADER LINE.
s_itab-col = 'B'.
s_itab-seq = '1'.
INSERT TABLE s_itab.
s_itab-col = 'A'.
s_itab-seq = '2'.
INSERT TABLE s_itab.
CLEAR s_itab.
READ TABLE s_itab INDEX 2.
WRITE: s_itab-col, s_itab-seq.
03-3.hashed table
hashed type의 인터널 테이블은 index가 없기 때문에 read table ~ index구문을 사용할 수 없다.
즉, READ TABLE ~ WITH TABLE KEY 혹은 WITH KEY 구문을 이용해서 인터널 테이블 데이터에 접근할 수 있다.
TYPES:BEGIN OF u_line,
col TYPE C,
seq TYPE i,
END OF u_line.
TYPES u_tab TYPE HASHED TABLE OF u_line WITH UNIQUE KEY col.
DATA u_itab TYPE u_tab WITH HEADER LINE.
u_itab-col = 'B'.
u_itab-seq = '1'.
INSERT TABLE u_itab.
u_itab-col = 'A'.
u_itab-seq = '2'.
INSERT TABLE u_itab.
READ TABLE u_itab WITH TABLE KEY COL = 'A'.
WRITE: u_itab-col, u_itab-seq.04.인터널 테이블 속도 비교 -> 요건은 시간이 있을때 해보자아.. (standard table 의 바이너리 리서치, sorted table의 성능 차이 등..)
05.인터널 테이블 명령어
05-1. 인터널 테이블 값 할당
MOVE itab1 TO itab2. ** itab1 = itab2
MOVE itab1[] TO itab2[]. ** itab1[] = itab2[].
MOVE-CORRESPONDING itab1 TO itab2. ** line type이 다른 경우, 'move-corresponding'을 통해 두 오브젝트 간 순서와 관계없이 같은 칼럼명에만 값을 할당할 수 있다.TYPES: BEGIN OF f_line,
col1 TYPE i,
col2 TYPE i,
END OF f_line.
DATA: gt_itab1 TYPE STANDARD TABLE OF f_line WITH HEADER LINE,
gt_itab2 TYPE STANDARD TABLE OF f_line,
gt_wa LIKE LINE OF gt_itab2.
DO 5 TIMES.
gt_itab1-col1 = sy-index.
gt_itab1-col2 = sy-index * 2 .
INSERT TABLE gt_itab1.
ENDDO.
MOVE gt_itab1[] TO gt_itab2.
LOOP At gt_itab2 INTO gt_wa.
WRITE: gt_wa-col1, gt_wa-col2.
ENDLOOP.* header line이 있으면 헤더라인과 인터널 테이블 이름은 같다.
이것을 구분하기 위해 인터널 테이블의 BODY를 [ ] 기호를 이용해 구분한다.
'MOVE gt_itab1[] to gt_itab2'에서 []기호를 쓴거는 해당 테이블의 바디 내용을 가리킨다.
즉, 헤더 라인이 있는 인터널 테이블의 이름은 헤더라인을 의미하고
헤더 라인이 없는 인터널 테이블의 이름은 자기 자신이 된다.
이러한 이유 때문에 예제에서는 헤더 라인의 유무에 따라 move gt_itab1[] to gt_itab2 구문을 사용하게 된것.
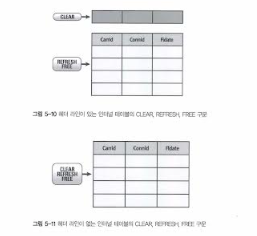
05-2. 인터널 테이블 초기화
다른 변수와 같이 인터널 테이블도 clear 할 수 있다.
인터널 테이블을 초기화 하는 구문은 clear, refresh, free가 있다.
- REFRESH: 인터널 테이블의 데이터만 지우고 메모리 공간은 그대로 가지고 있음
- CLEAR: 인터널 테이블의 내용을 지우고 할당된 메모리도 반환
DATA: BEGIN OF gb_line,
col1 TYPE i,
col2 TYPE i,
END OF gb_line.
DATA:gb_itab LIKE STANDARD TABLE OF gb_line WITH HEADER LINE.
gb_itab-col1 = '1'.
gb_itab-col2 = '2'.
INSERT TABLE gb_itab.
CLEAR gb_itab.
IF gb_itab IS INITIAL.
WRITE: 'internal table has no data.'.
FREE gb_itab.
ENDIF.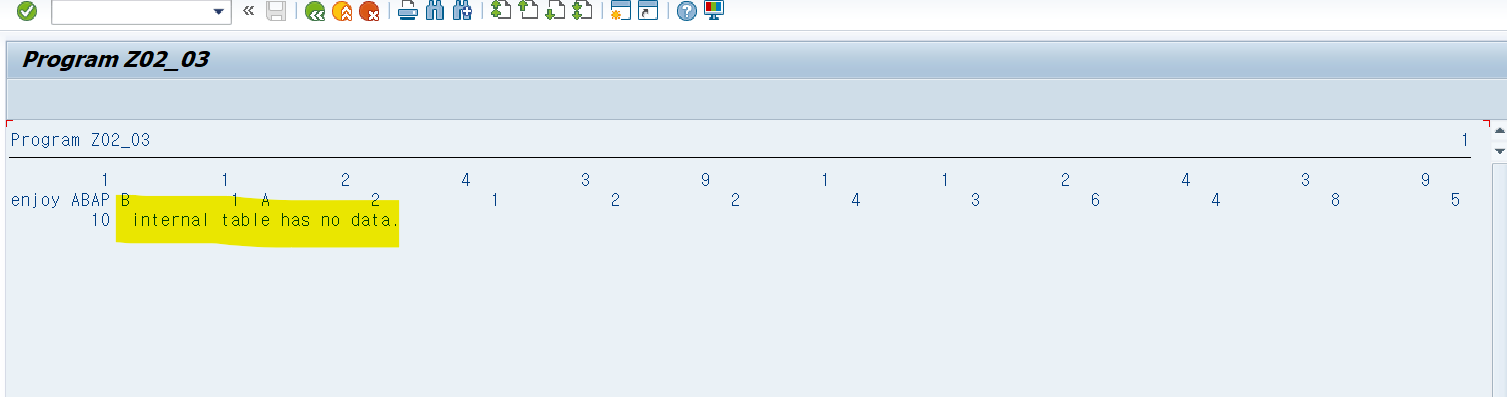
05-3. 인터널 테이블 정렬
05-3-1. SORT
stanradt 또는 hashed type의 인터널 테이블을 정렬할 수 있다.
테이블 키가 선언되지 않은 경우는 문자 타입의 칼럼들을 구성하여 KEY값으로 만든다.
SORT 정렬의 기본 값은 ASCENDING이다.
SORTED TABLE은 테이블 자체에서 정렬된 데이터를 가지고 있기 때문에 SORT 명령어를 사용하면 SYNTAX ERROR를 만나게 된다.
SORT ITAB [ASCENDING|DECSNDING]05-3-2. SORT 칼럼 지정
정렬이 필요한 칼럼을 임의로 지정하고 싶을때는 다음 구문을 사용한다.
아래 구문을 이용하면 table key를 이용하지 않고 f1 ~fn 칼럼(250개 한정)을 기준으로 정렬한다.
f1칼럼의 값 중에서 null이 존재하면 그 라인은 무시 한다.
SORT ITAB [ASCENDING|DESCENDING]
BY f1 [ASCENDING|DESCENDING]
....
fn [ASCENDING|DESCENDING].05-3-3. Stable SORT.
SORT명령어를 사용할때 마다 Sort sequence가 계속 변한다.
stable sort구문을 활용하면 sort sequence가 보존된다.
stable 옵션은 같은 데이터라도 처음 위치한 순서가 sort에 의애허 순번이 변경되지 않도록 하는 것이다.
SORT itab STABLE.
DATA: BEGIN OF mm_line,
col1 TYPE i,
col2 TYPE i,
END OF mm_line.
DATA mm_itab LIKE STANDARD TABLE OF mm_line WITH NON-UNIQUE KEY col1.
mm_line-col1 = 'A'.
mm_line-col2 =' 1'.
APPEND mm_line TO mm_itab.
mm_line-col1 = 'B'.
mm_line-col2 = '2'.
APPEND mm_line TO mm_itab.
SORT mm_itab.
PERFORM write_data.
SORT mm_itab by col1 col2.
PERFORM write_data.
SORT mm_itab by col2 DESCENDING col1 ASCENDING.
PERFORM write_data.
FORM write_data.
LOOP AT mm_itab INTO mm_line.
WRITE: / mm_line-col1, mm_line-col2.
ENDLOOP.
ENDFORM.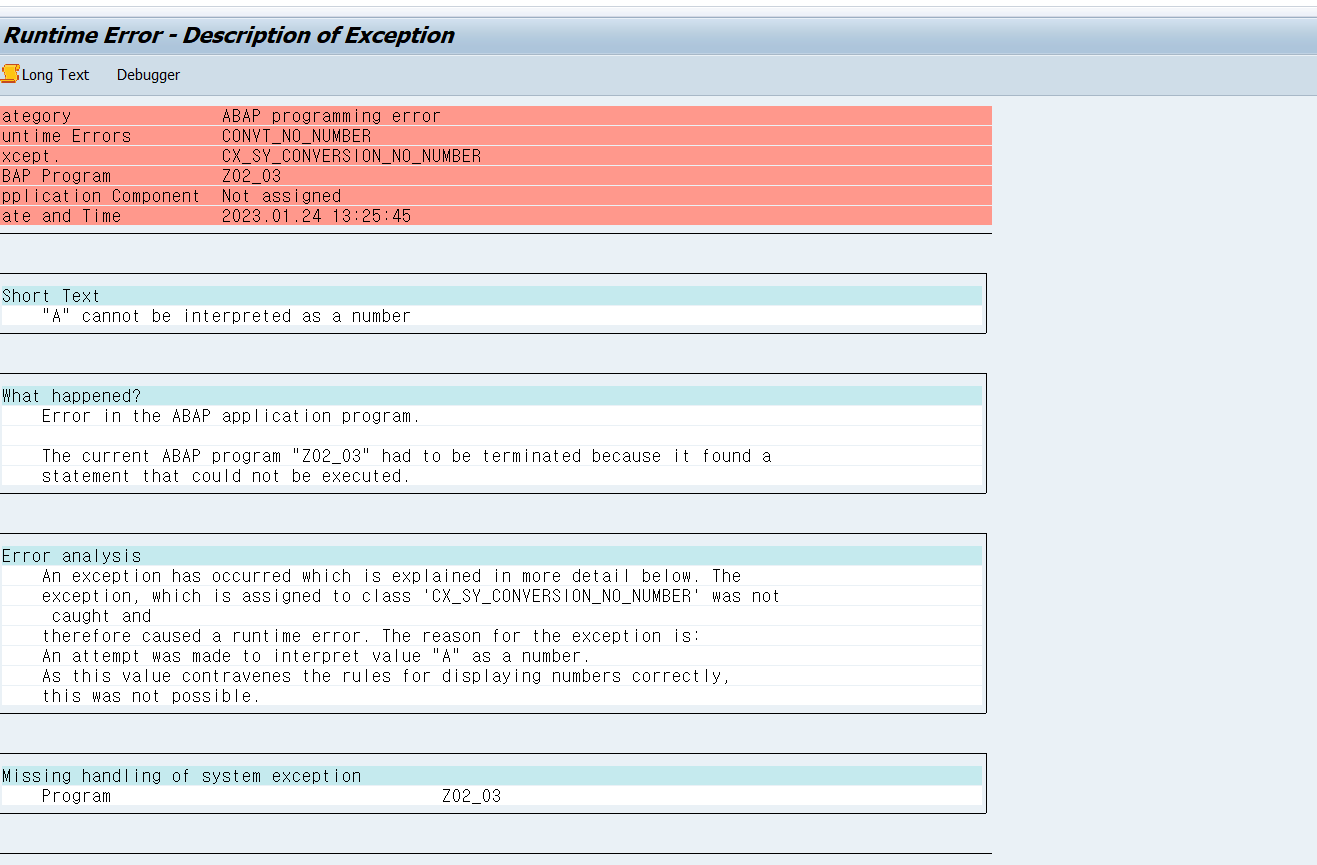
05-4 인터널 테이블 속성 알아내기 -> 이건 일단 현재 크게 중요하지 않으니 한바퀴 돌리고 하자
lines는 인터널 테이블에 존재하는 현재 라인 수를 반환하고
occurs는 인터널 테이블의 초기 라인 수를 반환한다.
kind는 인터널 테이블의 종류를 반환하며 (T =standard table, S= sorted table, H= hashed table을 의미함).
06.인터널 테이블 테이터 추가
06-1. insert 구문
06-1-1. table key를 이용해 한 라인 추가
한 라인을 삽입하려면, 다음 구문을 사용하며, key값을 이용해서 인터널 테이블에 라인을 추가한다.
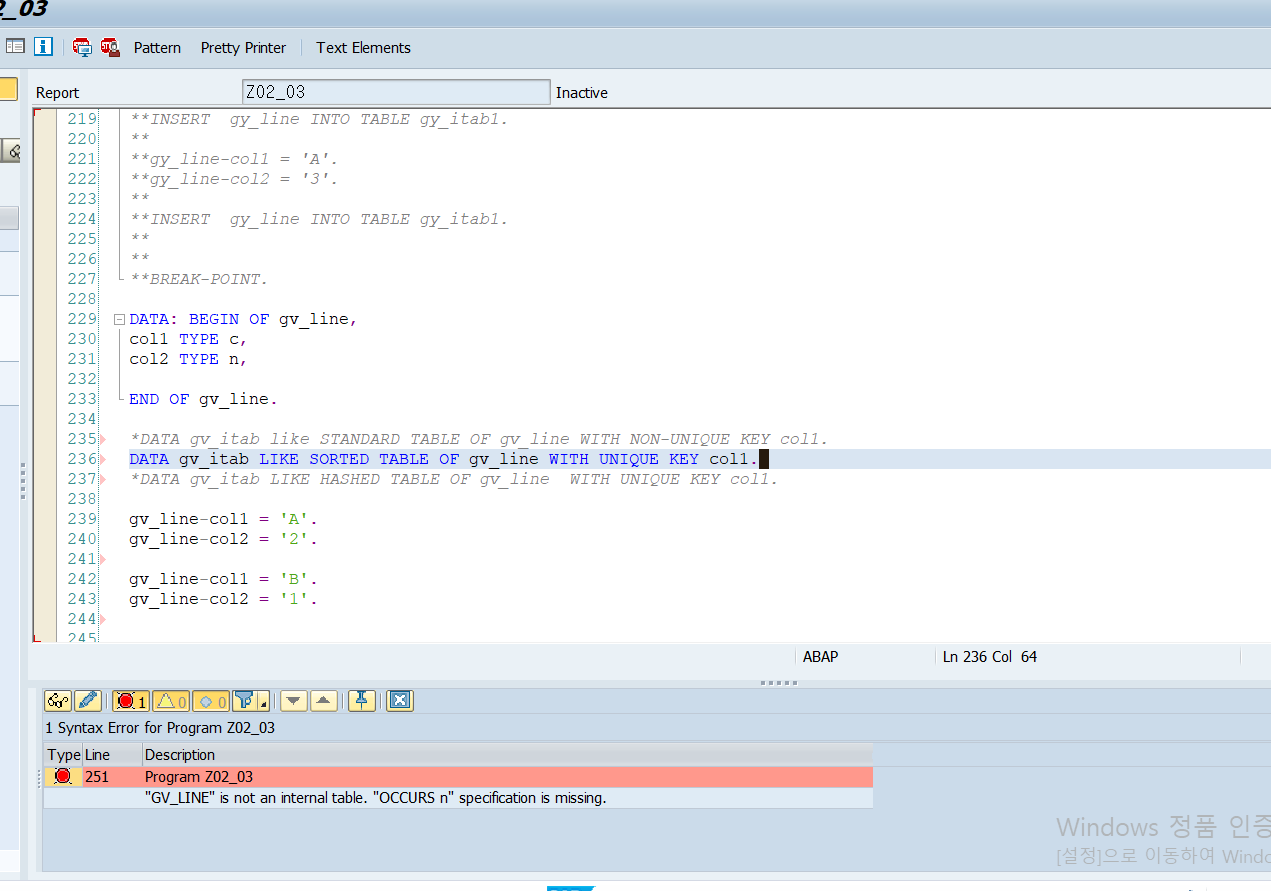
insert가 성공하면, 시스템 변수 SY-SUBRC에 0이 저장된다.
인터널 테이블이 UNIQUE KEY 값을 가지는 경우라면, INSERT 구문 수행 시 같은 Key 값이 존재하면
SY-SUBRC에 4 값을 반환하고 덤프에러는 발생하지 않는다.
INSERT line INTO table itab.06-1-2. table key를 이용해 여러 라인 추가
itab1 과 itab2 테이블은 같은 line type 이어야 한다.
INSERT lines OF itab1 [FROM n1] [TO n2] INTO TABLE itab2.DATA: BEGIN OF gh_line,
col1 TYPE c,
col2 TYPE i,
END OF gh_line.
DATA gh_itab1 LIKE STANDARD TABLE OF gh_line with NON-UNIQUE KEY col1.
*TYPE을 쓰면 에러 남.. WITH NON- UNIQUE KEY col1안쓰면 에러남.. 이 의미에 대해서 더 이해할 필요가 있음..
DATA gh_itab2 LIKE SORTED TABLE OF gh_line with NON-UNIQUe KEY col1.
gh_line-col1 = 'B'.
gh_line-col2 = '1'.
INSERT gh_line INTO TABLE gh_itab1.
gh_line-col1 = 'A'.
gh_line-col2 = '2'.
INSERT gh_line INTO TABLE gh_itab1.
gh_line-col1 = 'C'.
gh_line-col2 = '3'.
INSERT gh_line INTO TABLE gh_itab1.
INSERT LINES OF gh_itab1 INTO TABLE gh_itab2.
**INSERT LINE OF gh_itab1 FROM 1 TO 2 INTO TABLE gh_itab2.
LOOP AT gh_itab2 INTO gh_line.
WRITE: gh_line-col1, gh_line-col2.
ENDLOOP.06-1-3.index를 이용해 한 라인 추가.
index 구문을 이용하면 index 값 위치에 라인을 삽입할 수 있다.
이때는 hashed type의 인터널 테이블에는 사용할 수 없다.
성공하게 되면, SY-SUBRC변수를 0을 그리고 SY-TABIX 변수는 Index 값을 반환한다.
INSERT line INTO itab [Index idx].
INSERT lines OF itab1 INTO itab2 [Index idx].06-1-4. 인터널 테이블 타입에 따른 insert 효과(요런걸 잘 이해해야 코드 오류가 덜 나는 것 같다.. 아직 공부가 부족하지만 지금까지 공부해본 바에 의하면 내가 느끼는 바는 그러함..)
- standard table : 데이터는 인터널 테이블의 마지막 위치에 추가된다. append 구문과 같은 효과를 가진다.
- sorted table: 데이터는 인터널 테이블의 순서에 따라 추가된다. non- unique key 타입 이라면, duplicate line은 같은 key위에 추가된다..
- hashed table : 데이터는 table key의 haxh index 순서에 따라 추가 된다.
REPORT Z02_03.
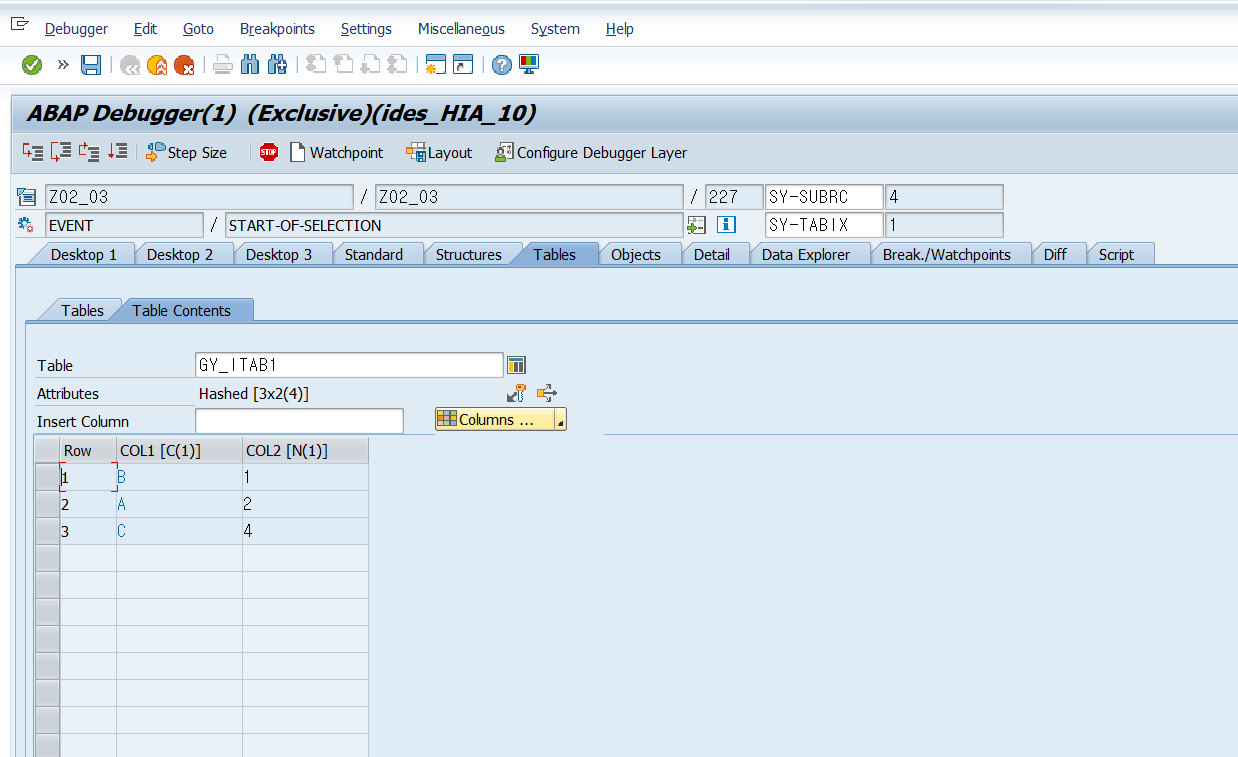
DATA: BEGIN OF gy_line,
col1 TYPE c,
col2 TYPE n,
END OF gy_line.
DATA gy_itab1 like STANDARD TABLE OF gy_line WITH NON-UNIQUE KEY col1.
* DATA gy_itab1 LIKE SORTED TABLE OF gy_line WITH NON- UNIQUE KEY col1.
* DATA gy_itab1 LIKE HASHED TABLE OF gy_line WITH NON-UNIQUE KEY col1.
gy_line-col1 = 'B'.
gy_line-col2 = '1'.
INSERT gy_line INTO TABLE gy_itab1.
gy_line-col1 = 'A'.
gy_line-col2 = '2'.
INSERT gy_line INTO TABLE gy_itab1.
gy_line-col1 = 'C'.
gy_line-col2 = '4'.
INSERT gy_line INTO TABLE gy_itab1.
gy_line-col1 = 'A'.
gy_line-col2 = '3'.
INSERT gy_line INTO TABLE gy_itab1.
BREAK-POINT.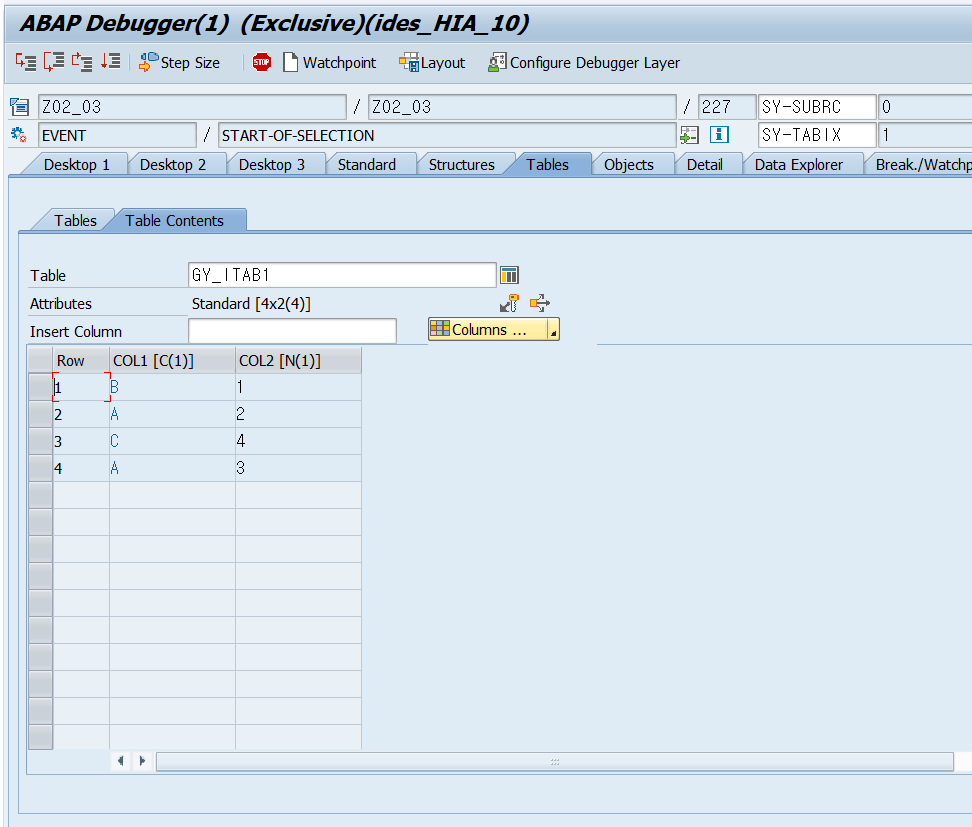

internal table 생성 시, like, type 그리고 with header line , with non-unique key를 언제 쓰는지에 대해서 더 공부가 필요함.
hashed table, sorted table, standard table의 특징과 차이점 그리고 특히 unique key 값에 대한 이해가 필요함
06-2. append구문을 이용한 table line 추가
INSERT 구문은 KEY와 INDEX를 이용해 인터널 테이블에 데이터를 추가할 수 있지만,
APPEND구문은 INDEX만 이용할 수 있다.
즉, Hashed TYPE의 인터널 테이블 에서는 사용할 수 없다.
06-2-1. 한 라인 추가
append를 한 후에는 시스템 변수 sy-tabix에 인터널 테이블에 추가된 라인의 index번호를 저장한다.
APPEND line TO itab.06-2-2. 여러 라인 추가
insert구문과 동일하게 인터널 테이블을 한번에 다른 인터널 테이블로 추가할 수 있다.
또한, 인터널 테이블 itab1의 인덱스 n1~ n2사이의 값을 itab2에 추가할 수 있다.
APPEND LINE OF itab1 TO itab2.
APPNED LINE OF itab1 [FROM n1] [TO n2] TO itab2.DATA: BEGIN OF gv_line,
col1 TYPE c,
col2 TYPE n,
END OF gv_line.
DATA gv_itab like STANDARD TABLE OF gv_line WITH NON-UNIQUE KEY col1.
**DATA gv_itab LIKE SORTED TABLE OF gv_line WITH UNIQUE KEY col1.
**DATA gv_itab LIKE HASHED TABLE OF gv_line WITH UNIQUE KEY col1.
gv_line-col1 = 'A'.
gv_line-col2 = '2'.
APPEND gv_line TO gv_itab.
gv_line-col1 = 'B'.
gv_line-col2 = '1'.
APPEND gv_line TO gv_itab.
gv_line-col1 = 'A'.
gv_line-col2 = '1'.
APPEND gv_line TO gv_itab.
gv_line-col1 = 'C'.
gv_line-col2 = '3'.
APPEND gv_line TO gv_itab.
BREAK-POINT.
DATA: BEGIN OF gv_line,
col1 TYPE c,
col2 TYPE n,
END OF gv_line.
*DATA gv_itab like STANDARD TABLE OF gv_line WITH NON-UNIQUE KEY col1.
DATA gv_itab LIKE SORTED TABLE OF gv_line WITH UNIQUE KEY col1.
DATA gv_itab2 LIKE SORTED TABLE OF gv_line WITH UNIQUE KEY col1.
*DATA gv_itab LIKE HASHED TABLE OF gv_line WITH UNIQUE KEY col1.
gv_line-col1 = 'A'.
gv_line-col2 = '2'.
gv_line-col1 = 'B'.
gv_line-col2 = '1'.
gv_line-col1 = 'A'.
gv_line-col2 = '1'.
gv_line-col1 = 'C'.
gv_line-col2 = '3'.
APPEND gv_line TO gv_itab.
APPEND LINES OF GV_ITAB FROM 0 TO 2 TO gv_itab2.
BREAK-POINT.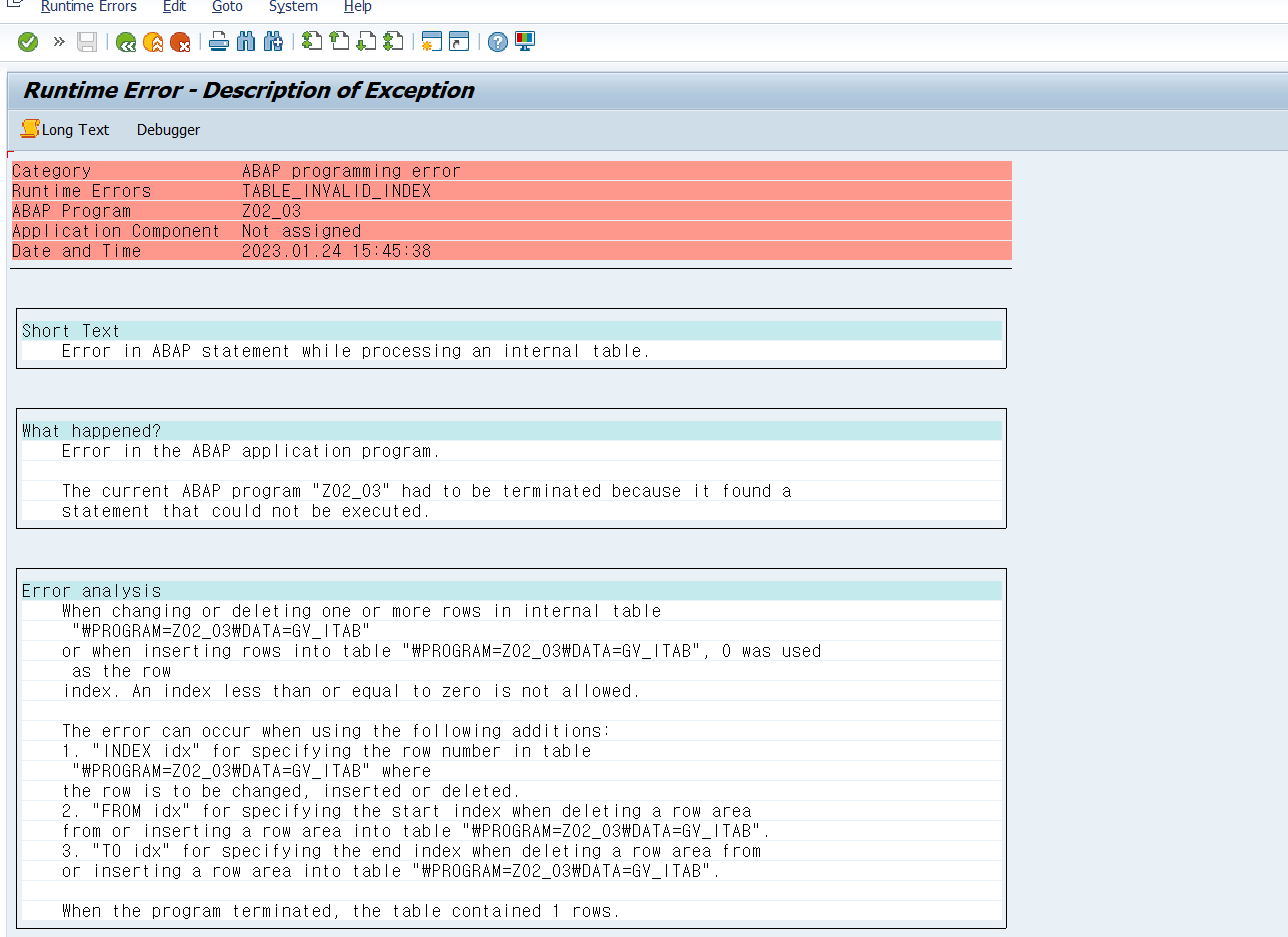
DATA: BEGIN OF gv_line,
col1 TYPE c,
col2 TYPE n,
END OF gv_line.
*DATA gv_itab like STANDARD TABLE OF gv_line WITH NON-UNIQUE KEY col1.
DATA gv_itab LIKE SORTED TABLE OF gv_line WITH UNIQUE KEY col1.
DATA gv_itab2 LIKE SORTED TABLE OF gv_line WITH UNIQUE KEY col1.
*DATA gv_itab LIKE HASHED TABLE OF gv_line WITH UNIQUE KEY col1.
gv_line-col1 = 'A'.
gv_line-col2 = '2'.
gv_line-col1 = 'B'.
gv_line-col2 = '1'.
gv_line-col1 = 'A'.
gv_line-col2 = '1'.
gv_line-col1 = 'C'.
gv_line-col2 = '3'.
APPEND gv_line TO gv_itab.
APPEND LINES OF GV_ITAB FROM 1 TO 3 TO gv_itab2.
BREAK-POINT.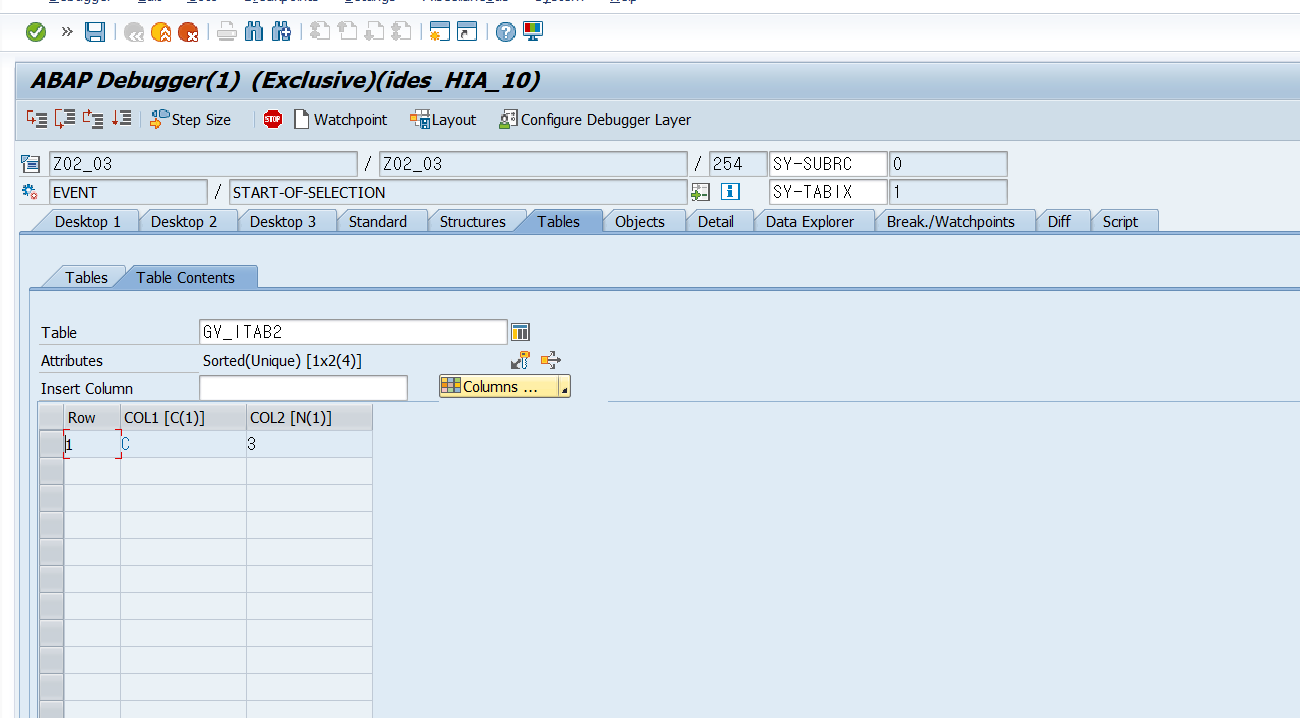
06-2-3. 인터널 테이블 타입에 따른 append 효과
- standard table: 추가되는 데이터는 인터널 데이블의 마지막에 추가된다. sorted by 옵션을 이용하여 key값 기준으로 descending 정렬을 하면서 추가 할 수 있다.
- sorted table: 데이터가 정렬된 상태로 인터널 테이블에 추가되도록 로직을 구성해야한다. 그렇지 않으면 dump error가 발생한다.
- hashed table: append 구문을 사용할 수 없다.
06-2-4. APPEND INITIAL LINE
인터널 테이블을 빈 공간에서 미리 생성한 후, 라인을 추가 할 수 있다.
sorted by 구문을 사용하면, 칼럼 f를 기준으로 descending 정렬을 수행하여 추가한다.
이때는 standard type의 인터널 테이블만 효력이 있으며, initial size로 크기를 지정해야한다.
APPEND INITIAL LINE TO itab
APPEND wa TO itab.
APPEND wa TO itab SORTED BY f.DATA: BEGIN OF gs_line,
col1 TYPE c,
col2 TYPE n,
END OF gs_line.
DATA gs_itab LIKE STANDARD TABLE OF gs_line INITIAL SIZE 2.
gs_line-col1 = 'C'.
gs_line-col2 ='1'.
APPEND gs_line TO gs_itab SORTED BY col1.
gs_line-col1 = 'A'. ** A값이 삭제된 이유는 INITIAL SIZE가 2 이기 때문에 DECENDING SORT APPEND 하면서 COL1 - a가 삭제 된것
gs_line-col2 = '2'.
APPEND gs_line TO gs_itab SORTED BY col1.
gs_line-col1 = 'B'.
gs_line-col2 = '3'.
APPEND gs_line TO gs_itab SORTED BY col1.
LOOP AT gs_itab INTO gs_line.
WRITE:/ gs_line-col1, gs_line-col2.
ENDLOOP.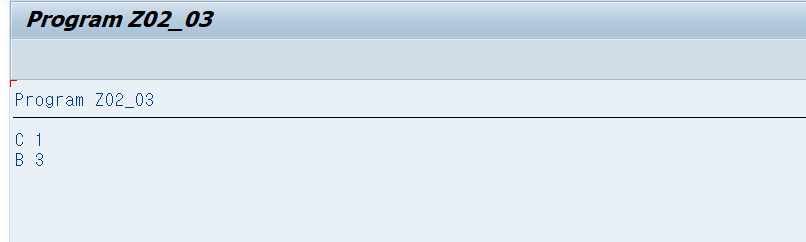
06-3. COLLECT
COLLECT 구문을 이용하여 인터너 ㄹ테이블의 숫자 타입 칼럼을 합산하는 기능을 수행한다.
key 값을 제외한 칼럼들은 Numeric Type( f,i,p)으로 선언 되어야 한다. - integer, floating number, packed number
collect 구문을 수행하면, 같은 key 값이 있을 때는 숫자 타입 칼럼을 합산하고 없을 때에는 append 기능을 수행한다.
key값이 없는 테이블은 char 타입 칼럼들을 기준으로 같은 작업을 수행한다.

COLLECT wa INTO itab.DATA: BEGIN OF gs_line,
col1(3) TYPE C,
col2(2) TYPE n,
col3 TYPE i,
END OF gs_line.
DATA gs_itab like STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY col1 col2.
gs_line-col1 = 'AA'. gs_line-col2 = '17'. gs_line-col3 = 660.
COLLECT gs_line into gs_itab.
gs_line-col1 = 'AL'. gs_line-col2 = ' 34'. gs_line-col3 = 220.
COLLECT gs_line INTO gs_itab.
gs_line-col1 = 'AA'. gs_line-col2 = '17'. gs_line-col3 = 340.
COLLECT gs_line INTO gs_itab.
LOOP AT gs_itab INTO gs_line.
WRITE: / gs_line-col1, gs_line-col2,gs_line-col3.
ENDLOOP.
DATA: BEGIN OF gs_line,
carrid TYPE sflight-carrid,
connid TYPE sflight-connid,
paymentsum TYPE sflight-paymentsum,
END OF gs_line.
DATA gs_itab LIKE STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY carrid connid WITH HEADER LINE.
data gt_sum LIKE STANDARD TABLE OF gs_line WITH non-UNIQUE KEY carrid connid WITH HEADER LINE.
select carrid connid paymentsum ** select구문 사용할때, 변수 사이에 ,로 구분하지 말것
INTO CORRESPONDING FIELDS OF TABLE gs_itab FROM sflight.
LOOP AT gs_itab.
COLLECT gs_itab INTO gt_sum.
ENDLOOP.
LOOP AT gt_sum.
WRITE: / gt_sum-carrid, gt_sum-connid, gt_sum-paymentsum.
ENDLOOP.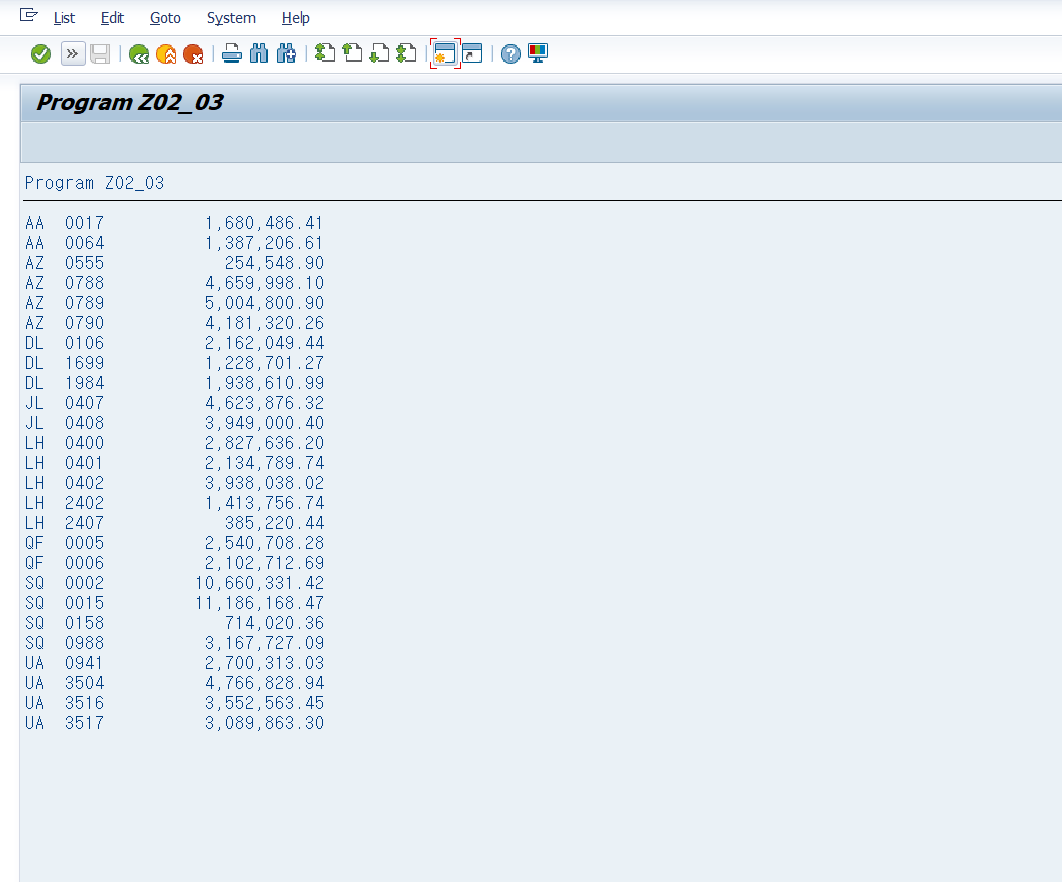
순서 1) 인터널 테이블을 두 개 선언한 후에 첫 번재 인터널 테이블 gs_itab에 데이터를 저장한다
순서 2)그리고 두 번재 인터널 테이블 gt_sum에 항공사와 운항 연결 id칼럼을 기준으로 paymentsum을 합산하면서 추가하게 된다.
07.인터널 테이블 데이터 변경
07-1. table key를 이용해 한 라인 변경
인터널 테이블의 한 라인을 변경하려면 MODIFY 구문을 사용한다.
해당 라인을 Key, Index 조건으로 찾아서 변경 할 수 있다.
transporting 구문을 이용하여 해당 칼럼만 변경 할 수 있다.
한 라인 전체를 변경하는 것보다 일부 칼럼만 변경하는 것이 당연히 성능이 좋긴 하지만, 영향은 크지 않다.
MODIFY TABLE itab FROM wa [TRANSPORTING f1,f2 ..].DATA: BEGIN OF gs_line,
col1(2) TYPE c,
col2 TYPE i,
col3 TYPE sy-datum,
END OF gs_line.
DATA:gt_itab LIKE STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY col1,col2.
gs_line-col1 = 'AA'.
gs_line-col2 = 26.
INSERT gs_line INTO gt_itab.
gs_line-col1 = 'AA'.
gs_line-col2 = 50.
INSERT gs_line INTO TABLE gt_itab.
gs_line-col1 = 'AA'.
gs_line-col2 = 26.
gs_linE-col3 = '20230125'.
MODIFY TABLE gt_itab FROM gs_line.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-col1, gs_line-col2, gs_line-col3.
ENDLOOP.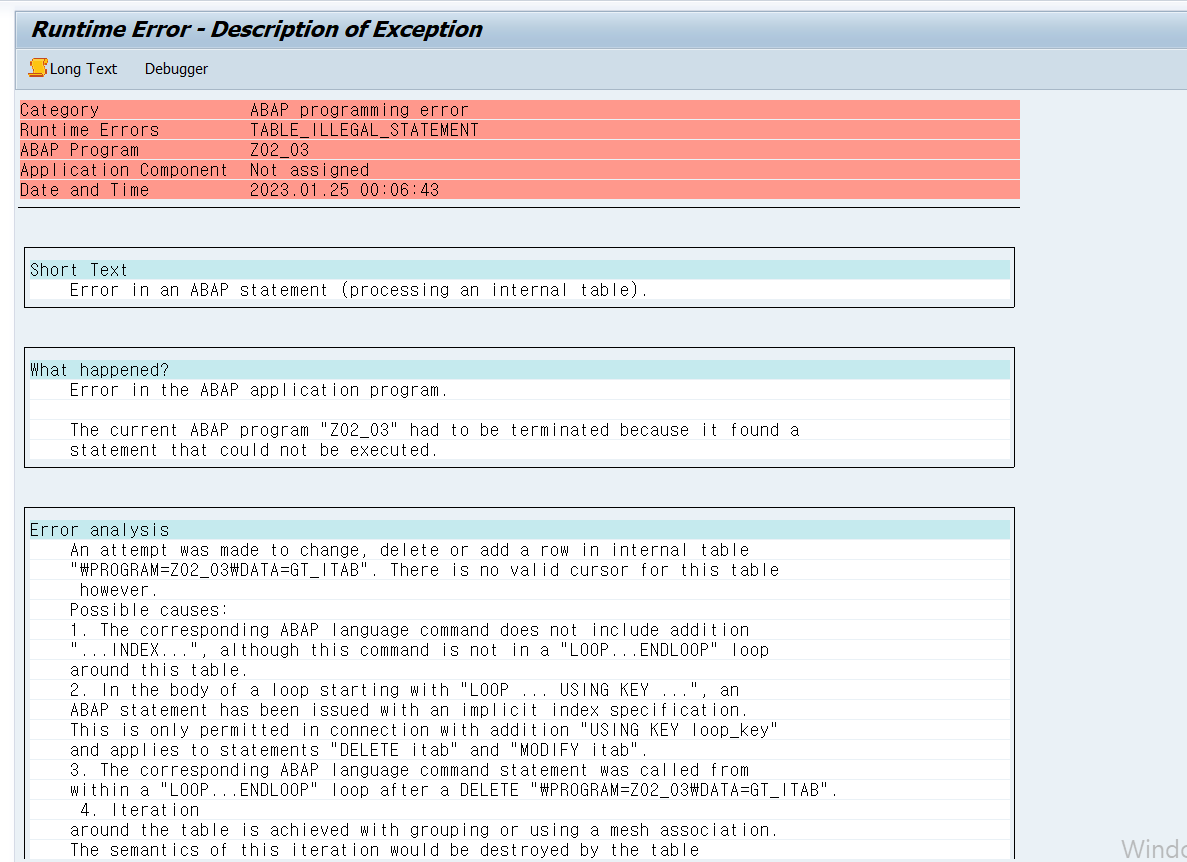
DATA: BEGIN OF gs_line,
col1(2) TYPE c,
col2 TYPE i,
col3 TYPE sy-datum,
END OF gs_line.
DATA:gt_itab LIKE STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY col1,col2.
gs_line-col1 = 'AA'.
gs_line-col2 = 26.
INSERT gs_line INTO TABLE gt_itab.
gs_line-col1 = 'AA'.
gs_line-col2 = 50.
INSERT gs_line INTO TABLE gt_itab.
gs_line-col1 = 'AA'.
gs_line-col2 = 26.
gs_linE-col3 = '20230125'.
MODIFY TABLE gt_itab FROM gs_line.
*MODIFY TABLE gt_itab FROM gs_line TRANSPORTING col3.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-col1, gs_line-col2, gs_line-col3.
ENDLOOP.
07-2. where 조건을 이용해 여러 라인 변경
하나 이상의 라인을 변경하고자 할때는 where구문을 사용한다.
MODIFY itab FROM wa TRANSPORTING f1,f2 ... WHERE cond.하고자 하는 거는 slight테이블에 있는 carrid, connid와 scarr테이블에 있는 carrid,connid, carrname을 inner join 하는 거.
sflight라는 테이블과 scarr라는 테이블에
carrid가 외래 키 값으로 연결 되어 있고
인터널 테이블은 sflight로 부터 carrid, connid 모두 가져오고
sflight와 scarr 테이블에 외래키 값인 carrnme과 carrid를 기준으로
carrid가 추가 될때 마다 carrname을 가져오고 거기에 sflight에만 있는 connid를 붙이는 거
DATA: BEGIN OF gs_line,
carrid TYPE sflight-carrid,
carrname TYPE scarr-carrname,
fldate TYPE sflight-fldate,
END OF gs_line.
DATA gs_itab LIKE TABLE OF gs_line.
SELECT carrid connid INTO CORRESPONDING FIELDS OF TABLE gs_itab FROM sflight.
LOOP AT gs_itab INTO gs_line.
AT NEW carrid. ** 해당 칼럼에 새로운 값이 들어온 경우 실행 되는 명령어
SELECT SINGLE carrname INTO gs_line-carrname
FROM scarr WHERE carrid = gs_line-carrid.
MODIFY gs_itab FROM gs_line TRANSPORTING carrname WHERE carrid = gs_line-carrid.
** 새로운 carrid가 들어올때 마다 그 새로운 carrid에 해당하는 carrname가지고 오기
ENDAT.
WRITE: / gs_line-carrid, gs_line-carrname.
ENDLOOP.인터널 테이블을 loop처리 할때, 다음 4가지 구문을 사용할 수 있음
- AT FIRST : 인터널 테이블의 첫 번째 값이 실행될때 수행된다
- AT NEW f1: 칼럼 f1에 새로운 값이 들어올때 수행된다
- AT END OF f1: 칼럼 f1의 값이 마지막일 때 수행된다.
- AT LAST: 인터널 테이블의 마지막 값이 실행될때 수행된다.
07-3. index를 이용해 한 라인 변경 -> 이거 실습은 다시 해야함..
index를 이용하여 해당 라인의 값을 변경 할 수 있다.
index를 이용해 값을 변경하기 때문에 standart, sorted 테이블에서만 사용할 수 있다.
loop구문내에서는 index 옵션을 생략할 수 있다 (이 경우, 현재 인터널 테이블의 line index 값을 변경 하게 된다.)
MODIFY itab FROM wa [INDEX idx][TRANSPORTING f1,f2....]
MODIFY gt_itab FROM gs_line INDEX sy-tabix = MODITY gt_itab FROM gs_line.
*헤더 라인이 있는 인터널 테이블이라면, 다음 구문이 위 구문과 같은 역할을 수행한다.
MODITY gt_itab. *생략된 구문( FROM gs_iab INDEX sy-tabix)08. 인터널 테이블 데이터 삭제
인터널 테이블의 한 라인을 삭제하려면 DELETE 구문을 사용한다.
해당 라인을 Key와 Index 조건으로 찾아서 삭제할 수 있다.
08-1. table key를 이용해 한 라인 삭제
non-unique key로 설정된 standard type의 경우 with table key구문은 중복된 key 데이터 중에서 한 건만 삭제한다.
DELETE TABLE itab [FROM wa].
DELETE TABLE itab WITH TABLE KEY k1= f1...08-2.where 조건을 이용해 여러 라인 삭제
하나 이상의 라인을 삭제하려면 WHERE구문을 사용한다.
DELETE itab WHERE cond.
DATA:BEGIN OF gs_line,
carrid TYPE sflight-carrid,
connid TYPE sflight-connid,
END OF gs_line.
DATA gt_itab LIKE TABLE of gs_line with NON-UNIQUE key carrid.
SELECT carrid connid
INTO CORRESPONDING FIELDS OF TABLE gt_itab FROM sflight.
DELETE gt_itab WHERE carrid = 'AA' AND connid = '0017'.
LOOP AT gt_itab INTO gs_line.
WRITE:/ gs_line-carrid, gs_line-connid.
ENDLOOP.08-3. index를 이용해 삭제
인덱스를 이용해 여러 라인을 한번에 삭제할 수도 있다.
당연히 hashed type의 인터널 테이블에서는 사용할 수 없다.
DELETE itab [INDEX idx].
DELETE itab FROM n1 TO n2. *n1~ n2 사이에 있는 데이터 삭제
DELETE itab FROM n1. * n1 이후에 있는 데이터 삭제
DELETE itab TO n2. * 처음 부터 n2에 있는 데이터 삭제DATA: BEGIN OF gs_line,
col1 TYPE i,
col2 TYPE i,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line.
DO 3 times.
gs_line-col1 = sy-index.
gs_line-col2 = sy-index * 2.
APPEND gs_line TO gt_itab.
ENDDO.
DELETE gt_itab INDEX 2.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-col1, gs_line-col2.
ENDLOOP.
08-4. adjacent duplicate구문을 이용해 중복 라인 삭제
adjacent duplicate 구문을 이용하여 중복된 라인을 삭제할 수 있다.
이 구문을 수행하기 이전에 sort구문으로 인터널 테이블을 정렬해야 원하는 결과를 얻을 수 있다.
DELETE ADJACENT DUPLICATE ENTRIES FROM itab
[COMPARING f1 f2 | ALL FIELDS].
*comparing 구문을 사용하지 않으면 table key 값이 중복된 데이터를 삭제한다.
이미 학습 하였듯이 key 값을 선언하지 않은 경우는 문자열의 선행필드 들이 default key로 구성된다..DATA : BEGIN OF gs_line,
carrid TYPE sflight-carrid,
connid TYPE sflight-connid,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line.
SELECT carrid connid INTO CORRESPONDING FIELDS OF TABLE gt_itab FROM sflight.
DELETE ADJACENT DUPLICATES FROM gt_itab COMPARING connid.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-carrid, gs_line-connid.
ENDLOOP.
DATA : BEGIN OF gs_line,
carrid TYPE sflight-carrid,
connid TYPE sflight-connid,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line.
SELECT carrid connid INTO CORRESPONDING FIELDS OF TABLE gt_itab FROM sflight.
DELETE ADJACENT DUPLICATES FROM gt_itab.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-carrid, gs_line-connid.
ENDLOOP.
09. 인터널 테이블 읽기
인터널 테이블에서 원하는 데이터를 읽으려면 READ 구문을 사용한다.
만일 헤더 라인이 있으면 헤더 라인으로 복사되고, 그렇지 않으면 Work area에 복사해야한다.
09-1. table key 이용
key 값을 이용하여 값을 찾을 수 있다.
result는 read 결과를 저장하게 되는 wrok area 이다.
헤더 라인이 존재하는 인터널 테이블은 into~ 이하를 생략하고 인터널 테이블 이름 자체를 Work area로 사용하여도 된다 (= header line).
성공하면 SY-SUBRC 변수에 0을 반환하고,
실패 하면 4를 반환한다.
SY-TABIX 변수는 Line의 Index를 반환 한다.
READ TABLE itab FROM wa INTO RESULT.
READ TABLE itab WITH TABLE KEY f1,f2... INTO RESULT. ** 이경우, 같은 칼럼을 여러번 사용할 수 없다DATA: BEGIN OF gs_line,
carrid TYPE scarr-carrid,
carrname TYPE scarr-carrname,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line with non-UNIQUE key carrid.
SELECT carrid carrname INTO CORRESPONDING FIELDS OF TABLE gt_itab FROM scarr.
gs_line-carrid = 'AA'.
READ TABLE gt_itab FROM gs_line INTO gs_line.
WRITE: / gs_line-carrid, gs_line-carrname.
CLEAR: gs_line.
READ TABLE gt_itab WITH TABLE KEY carrid = 'AB' INTO gs_line.
WRITE: / gs_line-carrid, gs_line-carrname.
09-2. work area 할당
READ 구문 수행 결과를 Work area로 할당하는 구문이다
READ TABLE itab WITH KEY k1 --- INTO wa [COMPARING f1 f2]
[TRANSPORTING f1 f2]09-2-1. READ구문의 COMPARING 옵션
COMPARING 구문은 READ구문의 결괏값에 비교 조건을 추가한다.
즉, COMPARING 구문 다음에 기술된 field들이 work area의 값과 인터널 테이블에 존재하는 값이 같으면 SY-SUBRC = 0 을 반환하고 같지 않으면 SY-SUBRC = 2를 반환 한다.
DATA : BEGIN OF gs_line,
col1 TYPE c,
col2 TYPE i,
END OF gs_line.
DATA gt_itab LIKE SORTED TABLE OF gs_line with UNIQUE key col1.
gs_line-col1 = 'A'. gs_line-col2 = 1.
INSERT gs_line INTO TABLE gt_itab.
CLEAR gs_line.
gs_line-col1 = 'B'. gs_line-col2 = 2.
INSERT gs_line INTO TABLE gt_itab.
CLEAR gs_line.
gs_line-col1 = 'A'.
READ TABLE gt_itab INTO gs_line FROM gs_line COMPARING col2.
WRITE: / 'SY-SUBRC is :', SY-SUBRC.
WRITE:/ 'result is :', gs_line-col1, gs_line-col2.
09-2-2. READ구문의 TRANSPORTING옵션
TRANSPORTING은 READ한 결과를 해당 칼럼만 TARGET에 저장하는 기능을 수행한다.
DATA: BEGIN OF gs_line,
col1 TYPE C,
col2(7) TYPE C,
END OF gs_line.
DATA gt_itab LIKE SORTED TABLE OF gs_line with UNIQUE key col1.
DATA gt_wa LIKE LINE OF gt_itab.
gs_line-col1 = 'A'.
gs_line-col2 = 'First'.
INSERT gs_line INTO table gt_itab.
CLEAR gs_line.
gs_line-col1 = 'B'.
gs_line-col2 = 'Second'.
INSERT gs_line INTO table gt_itab.
CLEAR gs_line.
gs_line-col1 = 'A'.
READ TABLE gt_itab WITH TABLE KEY col1 = 'A' INTO gt_wa TRANSPORTING col2.
WRITE: / 'COL is :', gt_wa-col1,gt_wa-col2.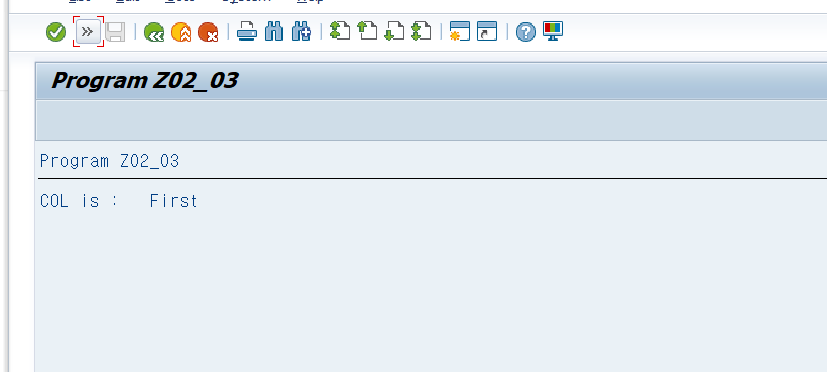
09-3. index를 이용해 read 구문 수행
index를 이용하여 해당 라인의 값을 읽을 수 있다.
index를 이용하기 때문에, hashed type의 인터널 테이블에서는 사용할 수 없다.
성공 시에는 SY-SUBRC 변수에 0을 반환하고 실패 시에슨 4를 반환한다.
그리고 SY-TABIX에는 인터널 테이블의 Index 순번이 저장 된다.
DATA: BEGIN OF gs_line,
col1 TYPE C,
col2 TYPE C,
END OF gs_line.
DATA gt_itab LIKE SORTED TABLE OF gs_line with UNIQUE key col1.
gs_line-col1 = 'A'. gs_line-col2 = 'First'.
INSERT gs_line INTO TABLE gt_itab.
CLEAR gs_line.
gs_line-col1 = 'B'. gs_line-col2 = 'Second'.
INSERT gs_line INTO TABLE gt_itab.
CLEAR gs_line.
READ TABLE gt_itab INTO gs_line INDEX 2.
WRITE: / ' col1 :',gs_line-col1, 'col2 : ', gs_line-col2.
09-4. read binary search. -> 이건 다시 하자
standard type의 인터널 테이블을 READ할 때, Binary search를 이용할 수 있음.
binary search 대상 칼럼을 기준으로 정렬한 후에 사용하며, READ 속도가 일반 READ 속도보다 빠르다.
READ TABLE itab KEY k1 = f1 INTO result BINARY RESEARCH.
'SAP셀프스터디 > 22일만에 이지아밥 1회독 하기' 카테고리의 다른 글
| [chapter15] GRIID ALV(ABAP List View) (0) | 2023.01.27 |
|---|---|
| [chapter14] ABAP Object (7) | 2023.01.27 |
| [chapter02] Data Type (0) | 2023.01.23 |
| [chapter07] ABAP Dictionary (0) | 2023.01.17 |
| [chapter01] Package & CTS (0) | 2023.01.16 |

